On reproche souvent aux algorithmes de machine-learning l’opacité qui les entourent. Il est en effet difficile de comprendre comment les prédictions sont évaluées.
La manière dont fonctionnent les algorithmes supervisés, aussi complexes soient-ils, est connue. Mais ils restent difficiles d’appréhender en quoi une observation est prédite dans une classe plutôt qu’une autre. L’inaccessibilité des caractéristiques et du raisonnement qui ont conduit à faire une prédiction est communément appelée « effet boite noire ». La majeure partie des algorithmes supervisées en sont sujet et peuvent dans un certain nombre domaine poser problème.
Les arbres de décisions permettent d’éviter ce genre de difficulté il est en effet assez simple de parcourir l’arbre, et d’examiner progressivement les résultats intermédiaires. Une série d’opérations mathématiques simple nous conduisent progressivement aux résultats de la prédiction.
Les différents benchmarks soulignent un rapport performance/temps de calcul intéressant. Les arbres de décisions sont un ensemble d’algorithmes, il en existe plusieurs variantes dont les plus connu sont : le CART et le C4.5.
La visualisation d3.js proposée ici vise à faciliter et à améliorer la lisibilité de l’arbre, qui se base sur l’implémentation de l’arbre de décision de librairie sklearn en python.
Sur chaque nœud de l’arbre est appliqué une opération de calcul qui conduit à une division du data-set. Sur l’ensemble de ces nœuds, un certain nombre de caractéristiques et d’informations peuvent être recueillies.
Elles sont présentées de la manière suivante :
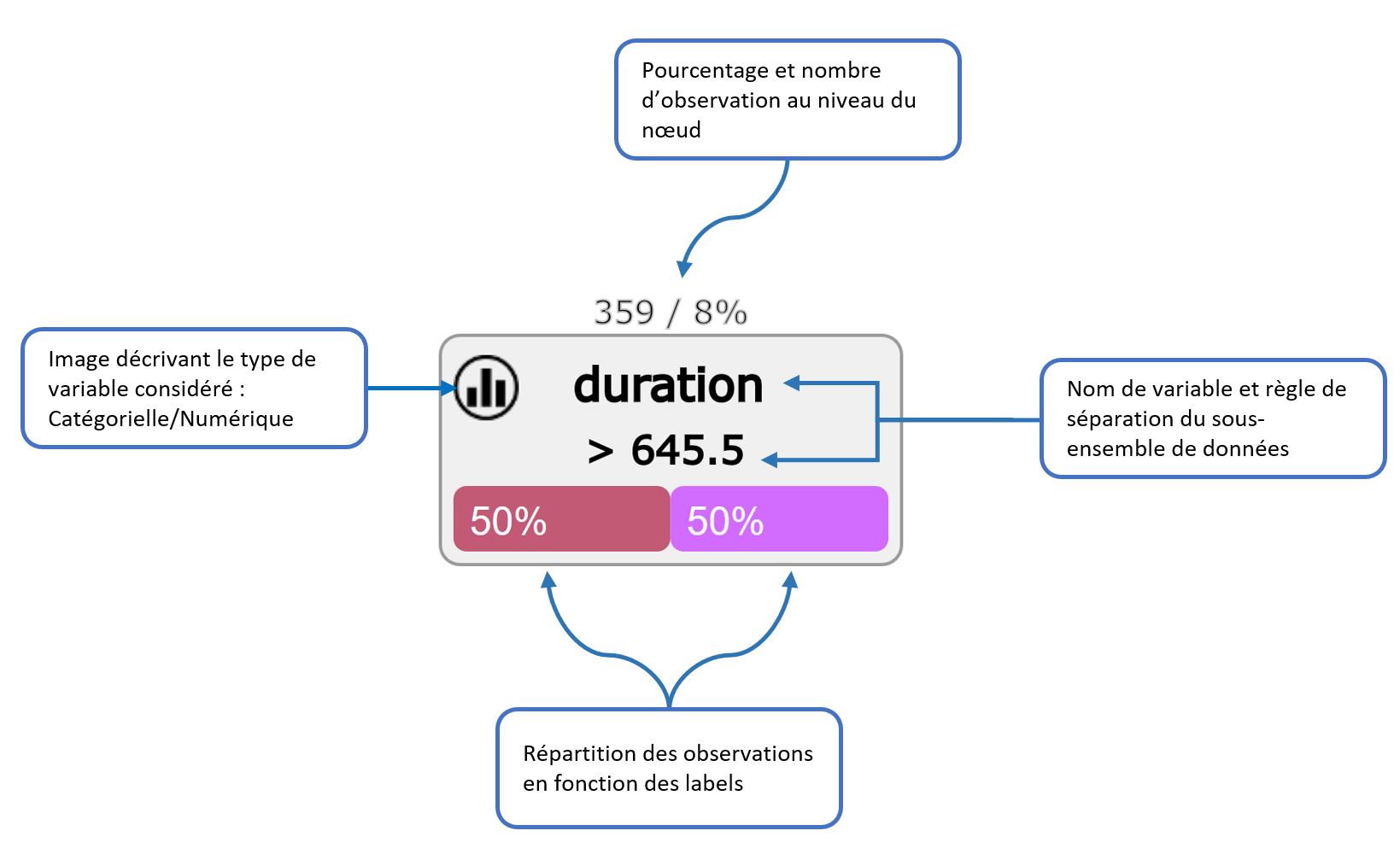
Le script python prend en entrée un fichier csv, qui s’occupe de faire un premier nettoyage en supprimant les lignes avec des valeurs manquantes, ou en encore en transformant les variables de type catégoriel (one-hot-encoding). L’implémentation du decision-tree sur scikit-learn ne prend pas encore en compte ce type de variable.
Deux fichiers json sont produits en sortie, afin de permettre de visualiser l’arbre de deux manières différentes : « StructureC1.json » , « StructureC2.json » . Ces deux fichiers ainsi que les paramètres (optionnelles) doivent être précisés dans le fichier index.html.
Privilégier Firefox pour voir du code en d3.js en cas de difficulté reporter vous ici
La vision interactive est disponible ici et le code complet peut être téléchargé ici
Conclusion
Alors que la course à la performance bat son plein, l’explicabilité des résultats des algorithmes a tendance à en pâtir. Les logiques sous-jacentes d’utilisation des données restent la plupart du temps inextricables.
Les arbres de décisions possèdent bien évidement des limites, mais leurs natures déchiffrables en font un excellent allier pour une première approche.
Cet algorithme peut être complété par une procédure de feature importance, afin de renforcer la compréhension du mécanisme de la prédiction.
References
[1] Huang, Jin, Jingjing Lu, and Charles X. Ling. « Comparing naive Bayes, decision trees, and SVM with AUC and accuracy. » Third IEEE International Conference on Data Mining. IEEE, 2003 [link]
[2] Kumar, Pardeep, Vivek Kumar Sehgal, and Durg Singh Chauhan. « A benchmark to select data mining based classification algorithms for business intelligence and decision support systems. » arXiv preprint arXiv:1210.3139 (2012) [link]
[3] P. Prettenhofer, Decision Tree Viewer (D3 and Sklearn) (2012) [link]
[4] A. Schumacher, See sklearn trees with D3 (2015 [link]