Avec l’émergence du deep-learning, la capacité de prédiction de ce type d’algorithme semble prometteuse. En témoigne les nombreux et derniers travaux publiés et qui montrent des capacités de prédiction jusque – là inégalées.
Nous vous proposons ici un nouveau dataset issue d’images satellitaires représentant différents types de toiture. L’ensemble est composé de 3000 images de dimensions et de qualités différentes ainsi qu’un fichier csv contenant les labels. L’objectif étant , avec une architecture deep-learning relativement simple, d’obtenir des résultats convaincants afin de détecter le type de toiture. Vous pouvez télécharger les données et le script complet ici.
Les toitures ont été réparties en quatre classes :

- La première classe est composée de toits à architecture simple, orientés horizontalement.
- La seconde classe est composée de toits à architecture simple, orientés verticalement.
- La troisième classe est composée de toits de bâtiments industriels et de toits d’immeubles.
- La quatrième classe est composée de bâtiments et maisons aux toits à architectures complexes.
Pour cet exercice, nous utiliserons principalement deux librairies : Keras ainsi que Tensorflow en backend. Le temps d’exécution dépend grandement du matériel utilisé. Pour exécuter les 150 étapes de l’algorithme ,comptez 8/12 heures avec un CPU i7/i5 classique et moins de 5 minutes avec une carte graphique du type Nvidia GTX1080Ti.
Cette architecture permet d’atteindre jusqu’à 0.98 d’accuracy. Le temps d’exécution pouvant être relativement long, vous pouvez importer le modèle et les poids de ce dernier. Les fichiers model.hdf5 et weigth.hdf5 contiennent respectivement le modèle et les poids du CNN.
Importation des librairies
import glob import os from os.path import basename import numpy as np import pandas as pd from PIL import Image import keras from keras import optimizers from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential from keras.layers import Dense, Dropout, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D,ZeroPadding2D from keras.callbacks import ModelCheckpoint from sklearn.cross_validation import train_test_split
La première étape consiste à récupérer les photos et les labels au bon format et de les transformer pour être utilisés par keras.
path="C://rootfop-detection//"
#load labels
m = pd.read_csv(path +"labels.csv", delimiter=",",header = None)
#load rooftop mage and resize
L=[]
train=np.array([])
#importation de images
images=glob.glob(path +"images"+"/*.*")
for i in range(0,len(images)):
im = Image.open(path +"images//"+m.iloc[i][0]+".jpg")
im_rz=im.resize((64,64), Image.ANTIALIAS)
#optionally if you want to save rezized images
#im_rz.save(path+"//resized//"+basename(images[i]), 'JPEG',quality=100,optimize=True)
L.append(np.array(im_rz))
data=np.array(L)
#transformation of labels into categorial variables to be interpreted by keras
y=pd.get_dummies(m.iloc[:,1])
#seperate data into training set and test set
x_train, x_test, y_train, y_test = train_test_split(data,y, train_size=0.8)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
y_train=np.array(y_train).astype('float32')
y_test=np.array(y_test).astype('float32')
x_train /= 255
x_test /= 255
Implémentation et compilation de l’architecture du réseau convolutif
L’architecture est relativement simple, elle est composée de quatre blocs, utilisant tous la fonction d’activation « ReLu ». L’optimiseur choisi est le « RMSprop ».
NB : Il existe d’autres fonctions d’activation tout comme il existe d’autres algorithmes d’ optimisation présents dans keras. (cf: Optimizers)
Chaque bloc est composé de deux couches de convolution, où est fixé pour chacune d’entre elles : Le filtre,le stride ,le padding ainsi qu’une couche de pooling et le dropout.
- Le «filtre »: correspond au nombre de neurones avec leurs poids associés.
- Le « stride » : correspond au nombre de pixels de déplacement du champ récepteur, évoluant en translation sur l ’image.
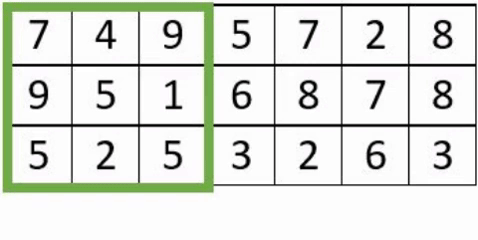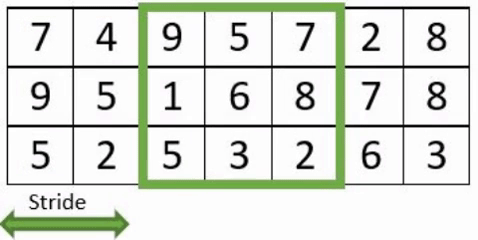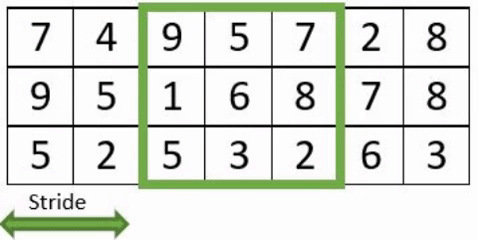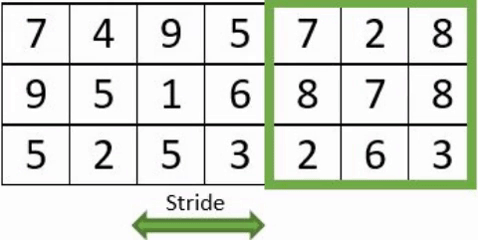
- Le « padding » : est l’ajout de de pixels artificiels autour de l’image, afin de faire des convolutions complètes. La taille des images n’étant pas nécessairement un multiple de la taille du stride, cela conduit à ne pas perdre d’information.
Exemple avec un stride à 3 avec et sans padding
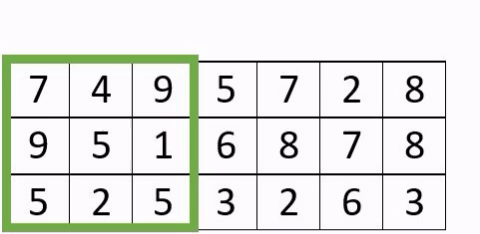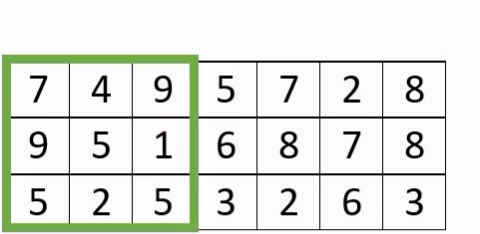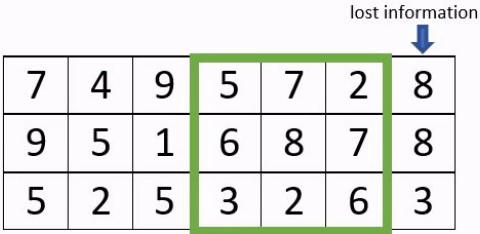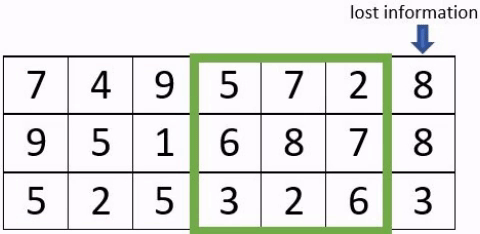
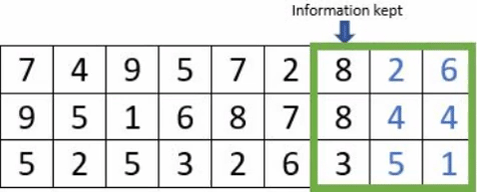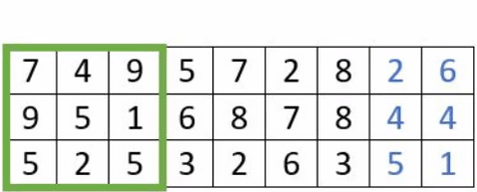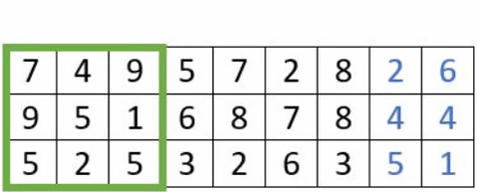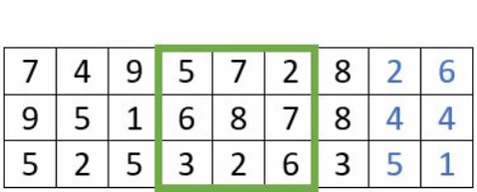
- Le «pooling» : La couche de regroupement est fréquemment utilisée dans les réseaux de neurones convolutionnels dans le but de réduire progressivement la quantité de variables. Il existe différents types de couche dites de «pooling» .En voici les caractéristiques de certaines d’entre elles:
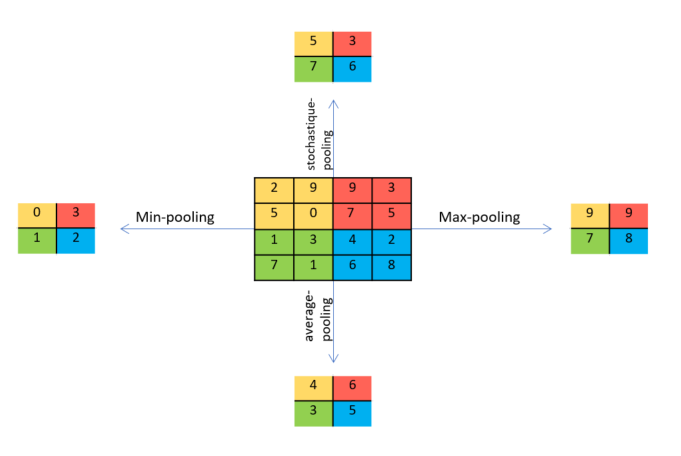
Intuitivement, une couche de pooling semble créer une perte d’informations. Cependant, associée à une couche de padding, qui ajoute des pixels à zéro autour de l’image, elle peut , au contraire permettre d’éliminer ou de limiter l’impact de ces rajouts. Le tout , en gardant un degré d’information optimal. Par exemple, une étape de maxpooling éliminera l’ensemble des pixels à zéro précédemment ajoutés.Néanmoins, son intérêt principal réside dans la prévention de l’overfitting et la réduction du coût de calcul, en réduisant le nombre de paramètres pour l’apprentissage .
- Le « dropout» :
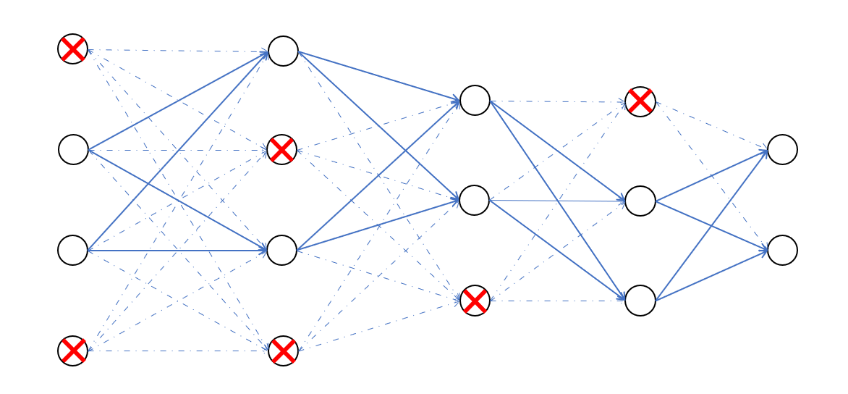 Il supprime aléatoirement et temporairement des liens entre les neurones, en fixant les poids de sortie à zéro. Cette procédure permet au CNN d’apprendre même s’il manque de l’information. Cette stratégie est implémentée afin de limiter l’overfitting. Le pourcentage de liens à déconnecter, est fixé dans keras.
Il supprime aléatoirement et temporairement des liens entre les neurones, en fixant les poids de sortie à zéro. Cette procédure permet au CNN d’apprendre même s’il manque de l’information. Cette stratégie est implémentée afin de limiter l’overfitting. Le pourcentage de liens à déconnecter, est fixé dans keras.
Le code python de l’architecture du réseau:
batch_size = 128
nb_classes = 4
epochs = 150
# start of architecture Convolutional neural network
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='same',
input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(110, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.15))
model.add(Conv2D(84, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(84, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.20))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.20))
model.add(Conv2D(32, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.20))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('relu'))
model.add(Dropout(0.25))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
# initiate RMSprop optimizer
opt = keras.optimizers.rmsprop(lr=0.001, decay=1e-7)
# Let's train the model using RMSprop
model.compile(loss='categorical_crossentropy',optimizer=opt,metrics=['accuracy'])
# checkpoint: save best model during the training
filepath=path+"weights.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=0, save_best_only=True, mode='max')
callbacks_list = [checkpoint]
Durant l’exécution du traitement, nous utilisons la technique dite de « data augmentation ». Elle consiste à créer à partir des images originales, de nouvelles images plus ou moins modifiées.
Dans notre cas, nous créons de nouvelles images avec des petites rotations et décalages (left-right) par rapport à l’original. Cette technique permet d’augmenter la taille du dataset, et permet la plupart du temps, d’améliorer la qualité de l’apprentissage. Tensorflow/keras propose plusieurs types de modification.
Exécution du CNN
#preprocessing and realtime data augmentation: data_generation = ImageDataGenerator( rotation_range=7, # randomly rotate images in the range (degrees, 0 to 180) width_shift_range=0.10, # randomly shift images horizontally (fraction of total width) height_shift_range=0.10, # randomly shift images vertically (fraction of total height) horizontal_flip=True, # randomly flip images vertical_flip=True) # randomly flip images data_generation.fit(x_train) # Fit the model model_param=model.fit_generator(data_generation.flow(x_train, y_train,batch_size=batch_size), steps_per_epoch=x_train.shape[0] // batch_size, epochs=epochs, validation_data=(x_test, y_test), callbacks=callbacks_list)
Cependant, le choix de génération doit rester pertinent. Dans notre cas, nous devons distinguer les maisons à toit horizontal et vertical. Une rotation de 90° deviendrait totalement contre-productive. Alors qu’une génération d’images, avec une rotation mineur <10°, peut s’avérer utile pour pallier les images des classes 1 et 2 qui ne sont pas parfaitement horizontales ou verticales.
Si pour vous le temps de calcul est trop long , vous pouvez toujours importer le model et les poids du meilleur résultat obtenu comme ceci:
from keras.models import load_model model = load_model(path+'model.hdf5') model.load_weights(path+'weights_best.hdf5')
References
[1] ABADI, Martín, BARHAM, Paul, CHEN, Jianmin, et al. TensorFlow: A System for Large-Scale Machine Learning. In : OSDI. 2016. p. 265-283. [link]
[2] KRIZHEVSKY, Alex, SUTSKEVER, Ilya, et HINTON, Geoffrey E. Imagenet classification with deep convolutional neural networks. In : Advances in neural information processing systems. 2012. p. 1097-1105. [link]
[4] SCHMIDHUBER, Jürgen. Deep learning in neural networks: An overview. Neural networks, 2015, vol. 61, p. 85-117.[link]
[2] TOKUI, Seiya, OONO, Kenta, HIDO, Shohei, et al. Chainer: a next-generation open source framework for deep learning. In : Proceedings of workshop on machine learning systems (LearningSys) in the twenty-ninth annual conference on neural information processing systems (NIPS). 2015. [link]
[5] ZEILER, Matthew D. et FERGUS, Rob. Visualizing and understanding convolutional networks. In : European conference on computer vision. Springer, Cham, 2014. p. 818-833. [link]